Advanced usage#
The standard functionality of the sensemakr, demonstrated in the previous section, will suffice for most users, most of the time. When needed, more flexibility can be obtained by employing the sensitivity functions of the package directly, such as: (i) functions for sensitivity plots (ovb_contour_plot, ovb_extreme_plot); (ii) functions for computing bias-adjusted estimates and t-values (adjusted_estimate, adjusted_t); (iii) functions for computing the robustness value and
partial R2 directly (robustness_value, partial_r2); and, (iv) functions for bounding the strength of unobserved confounders (ovb_bounds), among others. These functions are in the modules ovb_plots, bias_functions, sensitivity_statistics, and ovb_bounds but these are also automatically imported when import the package.
In this notebook we demonstrate how to use these functions in two examples.
The risks of informal benchmarking#
Informal “benchmarking” procedures have been widely suggested in the sensitivity analysis literature as a means to aid interpretation. It intends to describe how an unobserved confounder 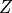 “not unlike” some observed covariate
“not unlike” some observed covariate 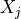 would alter the results of a study. Cinelli and Hazlett (2020) show why these proposals may lead users to erroneous conclusions, and offer formal bounds on the bias that could be produced by unobserved confounding
“as strong” as certain observed covariates.
would alter the results of a study. Cinelli and Hazlett (2020) show why these proposals may lead users to erroneous conclusions, and offer formal bounds on the bias that could be produced by unobserved confounding
“as strong” as certain observed covariates.
Here we use sensemakr to replicate the example in Section 6.1 of Cinelli and Hazlett (2020). This example provides a useful tutorial on how users can construct their own sensitivity contour plots with customized bounds, beyond what is offered by default on the package.
Simulating the data#
We begin by simulating the data generating process used in our example. Consider a treatment variable 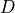 , an outcome variable
, an outcome variable 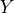 , one observed confounder
, one observed confounder 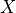 , and one unobserved confounder . Again, all disturbance variables
, and one unobserved confounder . Again, all disturbance variables 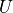 are standardized mutually independent gaussians, and note that, in reality, the treatment has no causal effect on the outcome .
are standardized mutually independent gaussians, and note that, in reality, the treatment has no causal effect on the outcome .
\begin{align} Z &= U_{z}\\ X &= U_{x}\\ D &= X + Z + U_d\\ Y &= X + Z + U_y \end{align}
Also note that, in this model: (i) the unobserved confounder is independent of ; and, (ii) the unobserved confounder is exactly like in terms of its strength of association with the treatment and the outcome. The code below creates a sample of size 100 of this data generating process. We make sure to create residuals that are standardized and orthogonal so that all properties that we describe here will hold exactly even in this finite sample.
[1]:
# imports statsmodels, numpy, and pands
import statsmodels.formula.api as smf
import numpy as np
import pandas as pd
# defines function to simulate orthogonal residuals
def resid_maker(n,df):
N = np.random.normal(0,1,n)
form = 'N~' +'+'.join(df.columns)
df['N'] = N
model = smf.ols(formula=form,data=df).fit()
e = model.resid
e = (e-np.mean(e))/np.std(e)
return(e)
# simulates data
n = 100
X = np.random.normal(0,1,n)
X = (X - np.mean(X))/np.std(X)
Z = resid_maker(n,pd.DataFrame({'x':X}))
D = X + Z + resid_maker(n,pd.DataFrame({'x':X,'z':Z}))
Y = X + Z + resid_maker(n,pd.DataFrame({'x':X,'z':Z,'d':D}))
Fitting the model#
In this example, the investigator does not observe the confounder . Therefore, she is forced to fit the restricted linear model 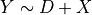 , resulting in the following estimated values
, resulting in the following estimated values
[2]:
# creates data.frame with the data
df = pd.DataFrame({'Y':Y,'X':X,'Z':Z,'D':D})
# runs OLS
model_ydx = smf.ols(formula='Y~D+X',data=df).fit()
# prints OLS summary
model_ydx.summary()
[2]:
| Dep. Variable: | Y | R-squared: | 0.500 |
|---|---|---|---|
| Model: | OLS | Adj. R-squared: | 0.490 |
| Method: | Least Squares | F-statistic: | 48.50 |
| Date: | Wed, 26 Jan 2022 | Prob (F-statistic): | 2.51e-15 |
| Time: | 21:12:01 | Log-Likelihood: | -162.17 |
| No. Observations: | 100 | AIC: | 330.3 |
| Df Residuals: | 97 | BIC: | 338.1 |
| Df Model: | 2 | ||
| Covariance Type: | nonrobust |
| coef | std err | t | P>|t| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| Intercept | 0 | 0.124 | 0 | 1.000 | -0.247 | 0.247 |
| D | 0.5000 | 0.088 | 5.686 | 0.000 | 0.325 | 0.675 |
| X | 0.5000 | 0.152 | 3.283 | 0.001 | 0.198 | 0.802 |
| Omnibus: | 3.229 | Durbin-Watson: | 1.722 |
|---|---|---|---|
| Prob(Omnibus): | 0.199 | Jarque-Bera (JB): | 2.614 |
| Skew: | 0.290 | Prob(JB): | 0.271 |
| Kurtosis: | 3.539 | Cond. No. | 2.41 |
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Note we obtain a large and statistically significant coefficient estimate of the effect of on (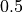 ). However, we know that the variable is not observed, and there is the fear that this estimated effect is in fact due to the bias caused by . On the other hand, let us suppose the investigator correctly knows that: (i) and have the same strength of association with and ; and, (ii) is independent of
. Can we leverage this information to understand how much bias a confounder “not unlike” could cause?
). However, we know that the variable is not observed, and there is the fear that this estimated effect is in fact due to the bias caused by . On the other hand, let us suppose the investigator correctly knows that: (i) and have the same strength of association with and ; and, (ii) is independent of
. Can we leverage this information to understand how much bias a confounder “not unlike” could cause?
Informal benchmarks#
Computing the bias due to the omission of requires two sensitivity parameters: its partial 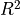 with the treatment and its partial with the outcome . How could we go about computing the bias that a confounder “not unlike ” would cause?
with the treatment and its partial with the outcome . How could we go about computing the bias that a confounder “not unlike ” would cause?
Intuitively, it seems that we could take as reference the observed partial of with and , and use those as the plausible values for the sensitivity parameters. So let us now compute those observed partial using the partial_r2(). For the partial of with the treatment, we also need to fit a treatment regression 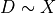 first.
first.
[3]:
# import sensemakr
import sensemakr as smkr
# fits treatment regression
model_dx = smf.ols(formula = 'D~X', data = df).fit()
# computes observed partial R2 of X with D and Y
r2dx = smkr.partial_r2(model_dx, covariates='X')
r2yx_d = smkr.partial_r2(model_ydx, covariates='X')
Once both partial are computed, we can determine the implied adjusted estimate due to an unobserved confounder using the adjusted_estimate().
[4]:
# computes adjusted estimate
informal_adjusted_estimate = smkr.adjusted_estimate(model = model_ydx,
treatment = "D",
r2dz_x = r2dx,
r2yz_dx = r2yx_d)
We can now plot the sensitivity contours with ovb_contour_plot() and add our informal benchmark with add_bound_to_contour().
[5]:
# draws sensitivity contours
smkr.ovb_contour_plot(model = model_ydx, treatment = "D", lim = 0.6)
# adds informal benchmark
smkr.add_bound_to_contour(r2dz_x = r2dx,
r2yz_dx = r2yx_d,
bound_value = informal_adjusted_estimate,
bound_label = 'Informal benchmark')

As we can see, the results of the informal benchmark are different from what we expected. The informal benchmark point is still far away from zero, and this would lead an investigator to incorrectly conclude that an unobserved confounder “not unlike ” is not sufficient to explain away the observed effect. Moreover, this incorrect conclusion occurs despite correctly assuming that: (i) and have the same strength of association with and ;
and, (ii) is independent of . See Section 6.1 of Cinelli and Hazlett (2020) for details of why this happens.
Formal bounds#
We now show how to compute formal bounds using the function ovb_bounds().
[6]:
# computes formal bounds
formal_bound = smkr.ovb_bounds(model = model_ydx,
treatment = 'D',
benchmark_covariates = "X",
kd = 1,
ky = 1)
In this function we specify the linear model being used (model.ydx), the treatment of interest (), the observed variable used for benchmarking (), and how stronger is in explaining treatment (kd) and outcome (ky) variation, as compared to the benchmark variable . We can now plot the proper bound against the informal benchmark.
[7]:
# contour plot contrasting informal vs formal bounds
smkr.ovb_contour_plot(model = model_ydx, treatment = "D",lim = 0.6)
smkr.add_bound_to_contour(r2dz_x = r2dx,
r2yz_dx = r2yx_d,
bound_value = informal_adjusted_estimate,
bound_label = 'Informal benchmark')
smkr.add_bound_to_contour(bounds = formal_bound,
bound_label = 'Proper bound')
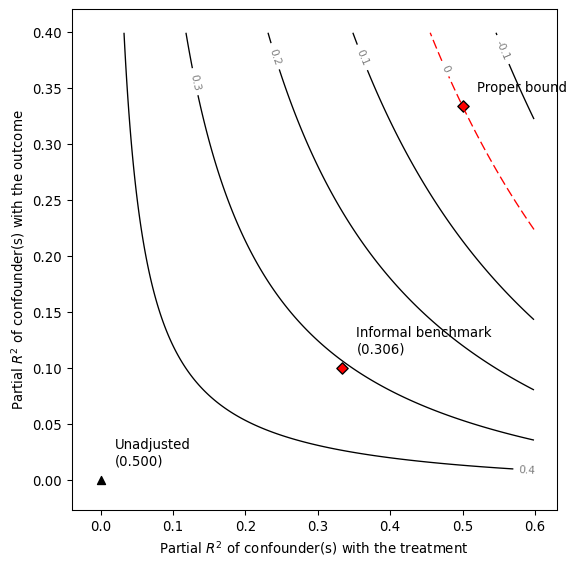
Note that, using the formal bounds, the researcher now reaches the correct conclusion that, an unobserved confounder similar to is strong enough to explain away all the observed association.
Manually providing input data#
We now demonstrate how to replicate the sensitivity analysis of the Darfur example (see Quickstart) without access to the microdata, using only usual statistics found in the regression tables. All results of the Darfur example, except the formal benchmark bounds as we explaim below, can be recoverded by simply providing: (i) the point estimate of directlyharmed (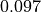 ); (ii) its estimated standard error (
); (ii) its estimated standard error (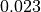 ); and, (ii) the degrees of freedom of the regression
(
); and, (ii) the degrees of freedom of the regression
(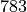 ). This type of “manual” analysis can be useful when reading or reviewing papers that did not perform sensitivity.
). This type of “manual” analysis can be useful when reading or reviewing papers that did not perform sensitivity.
[8]:
# computes the robustness value
smkr.robustness_value(t_statistic = 0.097/0.023, dof = 783)
[8]:
0 0.139787
dtype: float64
[9]:
# computes the partial R2
smkr.partial_r2(t_statistic = 0.097/0.023, dof = 783)
[9]:
0.022211153497507175
[10]:
# computes what the adjusted estimate would have been
# after adjusting for confounders with strength r2dz_x = .1, r2yz_dx = 0.15
smkr.adjusted_estimate(estimate = 0.097, se = 0.023, dof = 783, r2dz_x = .1, r2yz_dx = 0.15)
[10]:
0.013912997406333186
[11]:
# computes what the adjusted t-value would have been
# after adjusting for confounders with strength r2dz_x = .1, r2yz_dx = 0.15
smkr.adjusted_t(estimate = 0.097, se = 0.023, dof = 783, r2dz_x = .1, r2yz_dx = 0.15)
[11]:
0.6220526656946492
[12]:
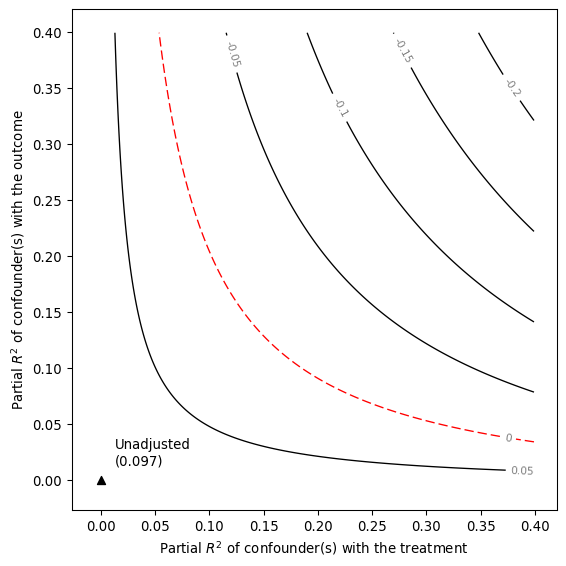
# contour plot of the point estimate
smkr.ovb_contour_plot(estimate = 0.097, se = 0.023, dof = 783)
[13]:
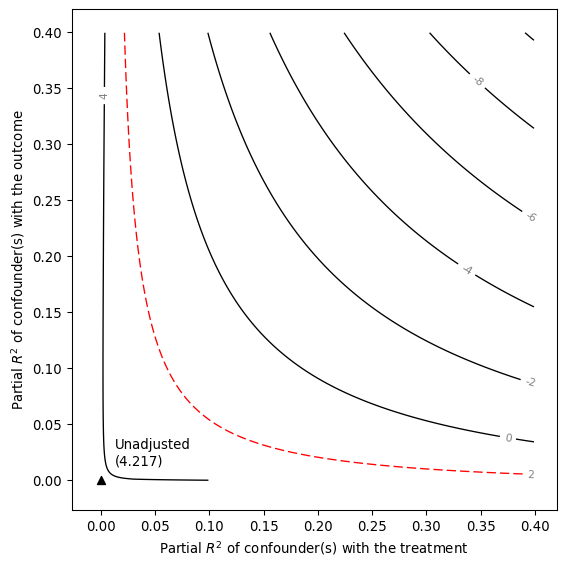
# contour plot of the t-value
smkr.ovb_contour_plot(estimate = 0.097, se = 0.023, dof = 783, sensitivity_of="t-value")
[14]:
# extreme plot
smkr.ovb_extreme_plot(estimate = 0.097, se = 0.023, dof = 783)

Finally, we show how users can compute bounds on the strength of confounding using only summary statistics, if the paper also provides a treatment regression table, i.e., a regression of the treatment on the observed covariates. Such regressions are sometimes shown in published works as part of efforts to describe the “determinants” of the treatment, or as “balance tests” in which the investigator assesses whether observed covariates predict treatment assigment. For the Darfur example, the
regression coefficient and standard errors (in parenthesis) of female for the outcome and treatment equation are -0.097 (0.036) and -0.232 (0.024). With these, we can now compute the formal bounds as shown below.
[15]:
# computes partial R2 based on t-value of female
r2yxj_dx = smkr.partial_r2(t_statistic = -0.232/0.024, dof = 783)
r2dxj_x = smkr.partial_r2(t_statistic = -0.097/0.036, dof = 783)
# computes bounds on the strength of Z if it were 1, 2 or 3 times as strong as female
bounds = smkr.ovb_partial_r2_bound(r2dxj_x = r2dxj_x,
r2yxj_dx = r2yxj_dx,
kd = [1,2,3],
ky = [1,2,3],
benchmark_covariates="female")
bounds
[15]:
| bound_label | r2dz_x | r2yz_dx | |
|---|---|---|---|
| 0 | 1x female | 0.009272 | 0.121575 |
| 1 | 2x female | 0.018544 | 0.243193 |
| 2 | 3x female | 0.027816 | 0.364854 |
[16]:
# computes adjusted estimate based on bounds
bound_values = smkr.adjusted_estimate(estimate = 0.0973, se = 0.0232, dof = 783,
r2dz_x= bounds['r2dz_x'], r2yz_dx=bounds['r2yz_dx'])
# draws contours
smkr.ovb_contour_plot(estimate = 0.097, se = 0.023, dof = 783)
# adds bounds
smkr.add_bound_to_contour(bounds = bounds, bound_value = bound_values)

References#
Cinelli, C. Hazlett, C. (2020) “Making Sense of Sensitivity: Extending Omitted Variable Bias”. Journal of the Royal Statistical Society, Series B (Statistical Methodology). ( link )